
Introduction
Hello, I am Hong Gao from Computing Laboratory. Fujitsu Research collaborated with Amadeus Code Inc., led by the renowned Japanese music producer Jun Inoue, to develop a generative AI-based music creators support tool. This blog introduces the background and technical mechanism behind this innovation.
In music production, creators often face challenges such as creative blocks and expressive limitations. They can spend days searching for inspiration and experimenting through trial and error. The music-generative AI we developed is designed to enhance creators' inspiration and support the creation of original music that goes beyond existing conventions. By leveraging AI technologies, we hope to unlock new possibilities for musical expression and elevate creativity beyond limits.
Bottleneck in Music Production
Even for professional composers, completing a piece of music can often take months. Music production is a complex process involving advanced musical theory, performance skills, and arrangement techniques to create art that resonates with audiences. According to Jun Inoue, the brainstorming phase generally represents about 70-80% of the total production time and can be particularly challenging for creators. This can result in a "creator's block," making it difficult to generate new ideas or break free from existing techniques and knowledge. Furthermore, the use of samples from existing songs, a common practice in hip-hop beat-making, requires careful consideration of copyright regulations. Addressing these legal concerns is not only essential for adhering to copyright law but also contributes significantly to the overall production expenses.
Next-Generation Music Production through Collaboration with Generative AI
Fujitsu Research has developed an innovative music-generative AI to overcome the inherent challenges in music production and empower music creators. This AI automatically generates music from text prompts. Moreover, generated pieces can be further extended by simply re-inputting them into the system.
To evaluate the potential of our music-generative AI, we conducted a collaborative experiment involving the musician Koyenma, a hip-hop beatmaker and DJ, the guitarist Yukihide "YT" Takiyama (also known as YT), and our co-researcher Inoue. The challenge was to create music using AI-generated materials, while intentionally excluding drums and bass. This decision was made because, in beat driven genres like hip-hop, the bass and drum parts are where creators typically showcase their unique skills and artistry. In this experiment, Koyenma added drums and bass to craft a compelling beat track, YT included an improvisational guitar solo, and Inoue introduced bass and synth. Remarkably, they produced five songs in just half a day, a process that traditionally could have taken several months.
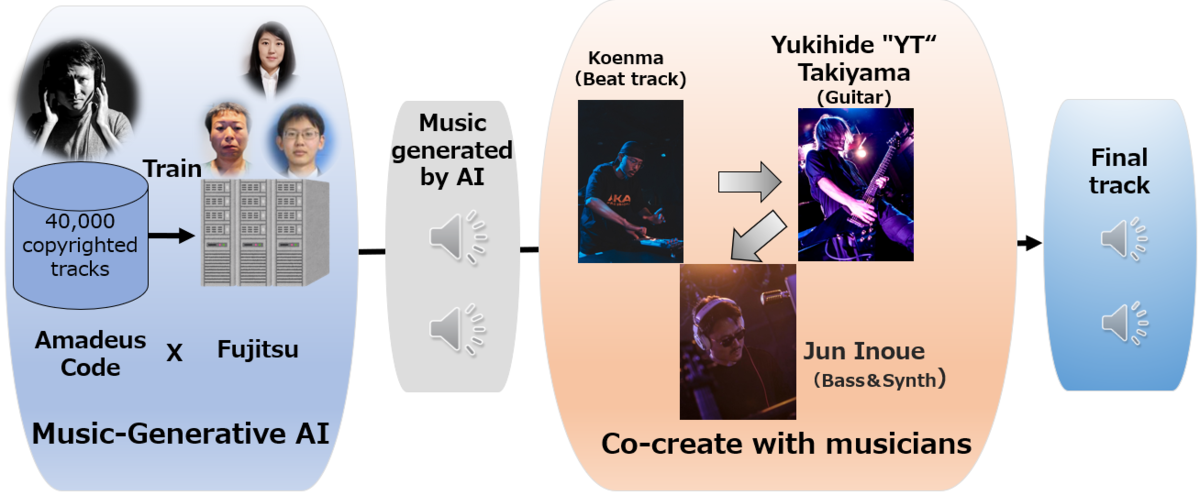
By automatically generating music prototypes with generative AI, our co-creation workflow significantly reduces the brainstorming time and improves the production efficiency. Creators can add their own arrangements and adjustments to the AI-generated materials. Furthermore, the innovative sounds, melodies, and styles suggested by the AI can provide creators with fresh inspirations, enabling them to explore expressions beyond their usual scopes. Through this co-creation process, creators can explore new forms of expression and unlock musical styles that were previously out of reach.
Below is shown a sample of AI-generated music alongside its final, refined version. youtu.be
The Mechanism of Music-Generative AI
Our AI-based music generation relies on a transformer-based model to process musical time-series data. It can capture time dependencies across the entire piece, such as melodies and chord progressions, and express complex musical structures. The music generation process consists of the following four steps (see diagram below).

The system starts by converting input text, which specifies the desired musical style—including elements such as genre, tempo, mood, and instrumentation (e.g., "Cool dance music")—into tokens. These tokens represent numerical encodings of the musical features described by the input text. This process, known as text encoding, leverages a model that has been pre-trained on a massive dataset comprising both musical compositions and their associated text descriptions. This pre-training phase allows the model to learn the intricate relationships between text descriptions and their corresponding musical attributes. For continuous music generation based on existing musical data, the same pre-trained model is employed to directly encode the relevant musical features.
Following text encoding, a transformer-based model predicts the sequence of music, defining its temporal flow, based on the generated tokens. This music sequence generation process infers the arrangement and progression of key musical elements, including melody, harmony, and rhythm, thereby constructing the fundamental structural framework of the music piece.
Subsequently, the generated music sequence tokens undergo an internal conversion into tokens that contains more detailed acoustic features.
Finally, a decoder is employed to convert these enhanced tokens into the final audio data, represented as a .wav file.
This integrated approach, combining multiple models, achieves a fully automatic music generation that is responsive to the specified input content. This marks a significant step towards democratizing music creation. We are excited to explore the potential of this technology that can empower musicians and unlock new creativity in the future.
Mitigation of Copyright Risks
To address copyright concerns in generative AI, we used a dataset of 40,000 original, high-quality music tracks (with an average of 3 minutes by track) owned by our research partner, Amadeus Code Inc. We trained our model from scratch, rather than fine-tuning an existing one, to mitigate copyright risks. This dataset is used for music sequence generation, feature extraction, and training text encoding models. Furthermore, the dataset includes detailed annotation data on the genre, instrumentation, and overall mood of each track, labeled by experienced professional musicians, thereby providing a solid foundation for the AI to accurately interpret and understand musical characteristics.
Efforts to Speed Up
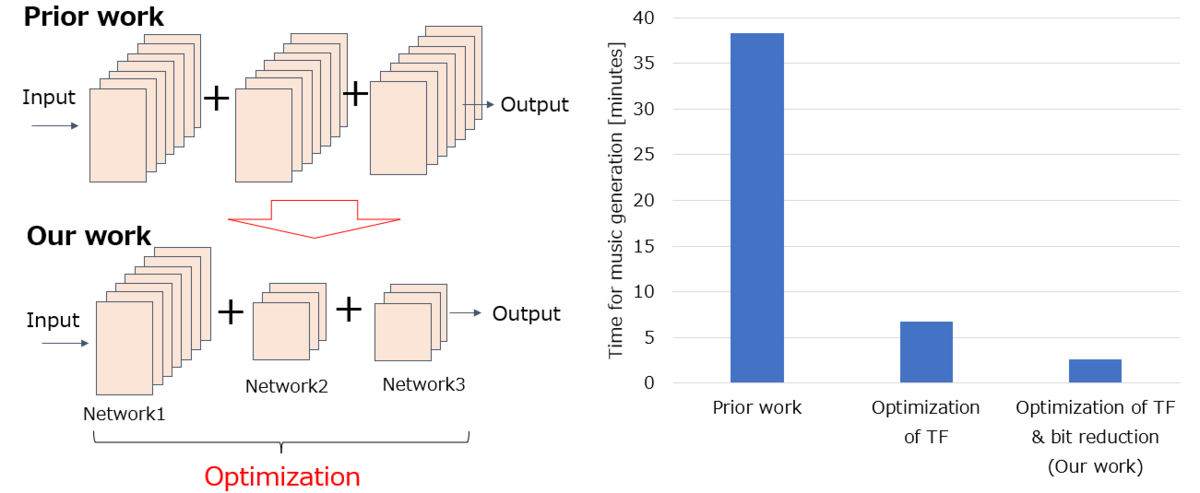
In a reference implementation of music generation AI with similar functionality, generating one minute of music (composed of four 15-second segments) required approximately 38.3 minutes of processing time on an A100 GPU. To address this performance bottleneck, we optimized the transformer structure (TF). We focused on reducing the weight of the acoustic token internal conversion part, which consists of a two-stage transformer. This part represented 88% of the overall processing time, making it the main target for efficiency improvements. As a result of TF optimizations, the execution time was substantially reduced from 38.3 minutes to 6.7 minutes. Furthermore, by implementing a bit reduction technology, we were able to further decrease the execution time to a mere 2.6 minutes, representing a 15-fold improvement in speed. Importantly, the speed enhancements had a negligible impact on the perceived quality of the generated music, as confirmed by a subjective evaluation of the optimized output.
Automatic Selection of Generated Music by Detecting Tempo and Chord Breakage
In general, AI-generated content such as music or images often contains distortions. Therefore, creators must carefully select pieces that are free from such flaws.
To alleviate this burden, we implemented a feature that automatically detects tempo and chord disruptions in the generated music. This feature filters out music exceeding a pre-defined threshold for the disruptions, reducing the selection effort and allowing creators to focus on more meaningful and creative aspects of music production.
However, since tempo and chord disruptions can sometimes inspire creators, the filtering option can be turned on or off.
Future Outlook
We have developed an AI that can automatically generate music based on text input. By leveraging data from Amadeus Code Inc., creators can use our technology for music production without copyright concerns, a common issue with traditional generative AI. Our optimized model also achieves practical generation speed-up. Future research will focus on supporting more genres, further speed improvements, and a more intuitive user interface. We aim to evolve AI together with creators, revolutionizing the future of music production.