
Hello, this is Hiraga, Kinoshita, and Ohtsuji from the Computing Laboratory at Fujitsu Research.
This article is the third installment of our four-part series reporting on SC25, the international conference held in St. Louis, USA in November 2025. We will introduce what the Computing Laboratory presented at the Fujitsu booth, along with trends in supercomputer performance rankings (Top500, Green500, IO500), and highlights from other events at the conference.

Fujitsu Technology Exhibition - Middleware Technologies Supporting the AI Era
From among the exhibits at the Fujitsu booth at SC25, we would like to introduce the GPU utilization improvement technologies presented by Fujitsu Research's Computing Laboratory.
Are You Getting the Most Out of Your Expensive GPUs?

While GPUs are essential for AI processing, are organizations truly utilizing them to justify their high costs? According to surveys based on actual measurements, approximately 70% of organizations report GPU utilization rates below 70%—essentially a "silent tax" on AI infrastructure. Improving GPU utilization has become a critical technical challenge in the AI era.
To address this challenge, the Computing Laboratory at Fujitsu Research exhibited the following three technologies.
AI Computing Broker - GPU Sharing Across Multiple Applications
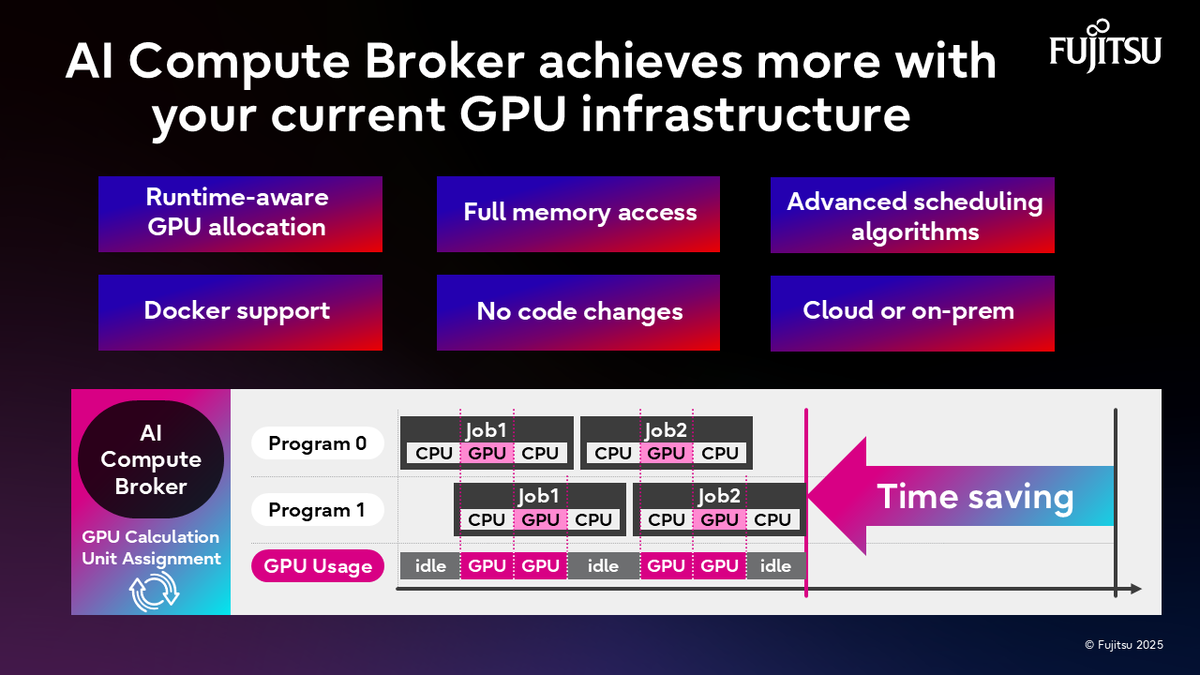
AI Computing Broker, or ACB, is a middleware technology that enables multiple AI applications to efficiently share GPU resources. ACB monitors AI program operations, automatically allocates GPUs when needed, and releases them to other programs as soon as they are no longer required.
A key feature of ACB is that while multiple applications share GPUs, each application can access the full GPU memory. Normally, sharing GPUs requires dividing the memory space, but ACB's proprietary technology allows each application to access the entire memory space as if it had exclusive use. Furthermore, existing AI applications can benefit from this without any code modifications. This enables organizations to process workloads equivalent to or greater than before with fewer GPUs, leading to cost reductions.
The exhibit was supported by a cross-functional team including colleagues from our Technology Strategy Unit, enabling productive discussions with visitors from around the world. ACB attracted strong interest, with many companies and research institutions making specific inquiries about implementation. ACB is currently progressing toward commercialization and productization, with proof-of-concept trials being conducted at multiple organizations.
ACB offers a free trial. For case studies and detailed information, please visit the ACB details page.
LLM Inference Acceleration - GPU Memory Expansion via High-Speed Distributed Data Store
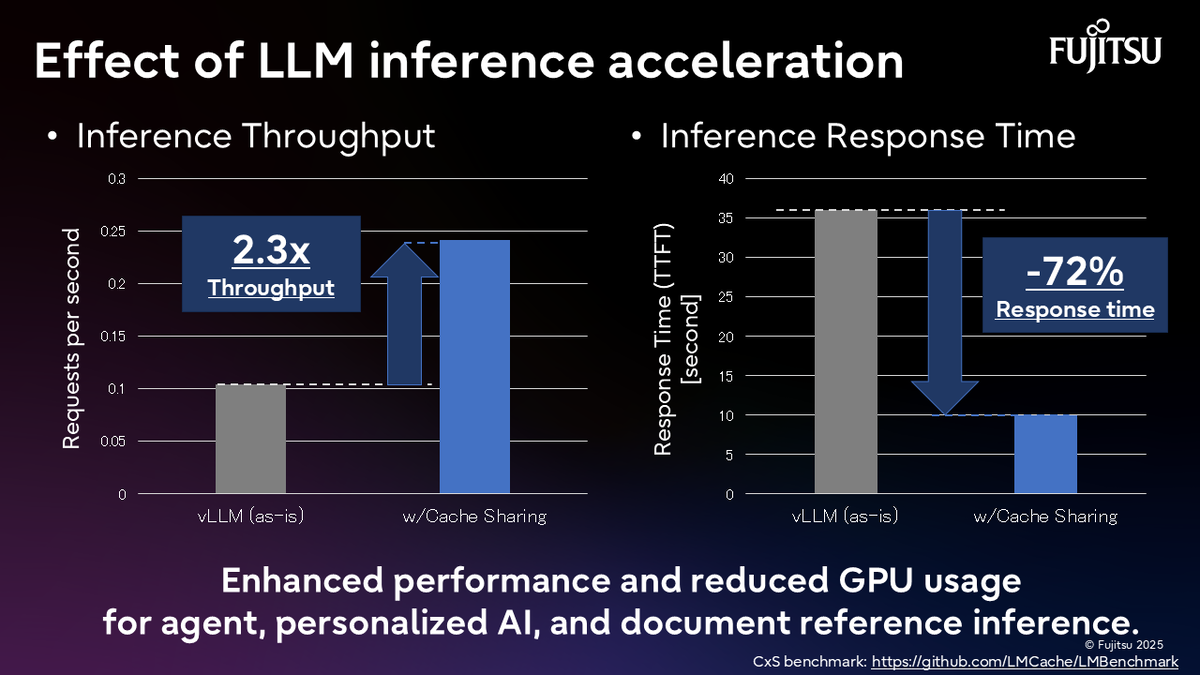
As LLM-powered applications such as chatbots and coding agents become widespread, handling large documents and lengthy chat histories has become a challenge. LLMs essentially need to recompute input information each time, resulting in longer processing times. This problem can be solved using caching, but GPU memory capacity is limited. Moreover, since each GPU maintains its own independent cache, queries about the same document assigned to different GPUs cannot reuse the cache and require recomputation. This leads to wasted GPU resources and degraded performance.
To solve this challenge, the Computing Laboratory is developing high-speed data store technology leveraging HPC techniques. This technology enables LLM caches to be shared across all GPUs and compute nodes. Previously, each GPU maintained its own cache separately, but by centralizing storage in a shared data store, any GPU can access the same cache.
At this exhibition, we presented early-stage experimental results and a chat demo showing the technology's effectiveness. Experiments confirmed a 2.3x improvement in inference performance (requests processed per second) and a 72% reduction in response time. We will continue research and development, exploring applications for systems handling long documents, such as chatbots and document Q&A systems. If you are interested in this technology, please feel free to contact us. For those interested in GPU efficiency for LLM inference infrastructure, we also encourage you to consider ACB, which is already available.
Interactive HPC - Streamlining AI Development Without Stopping Traditional HPC Jobs
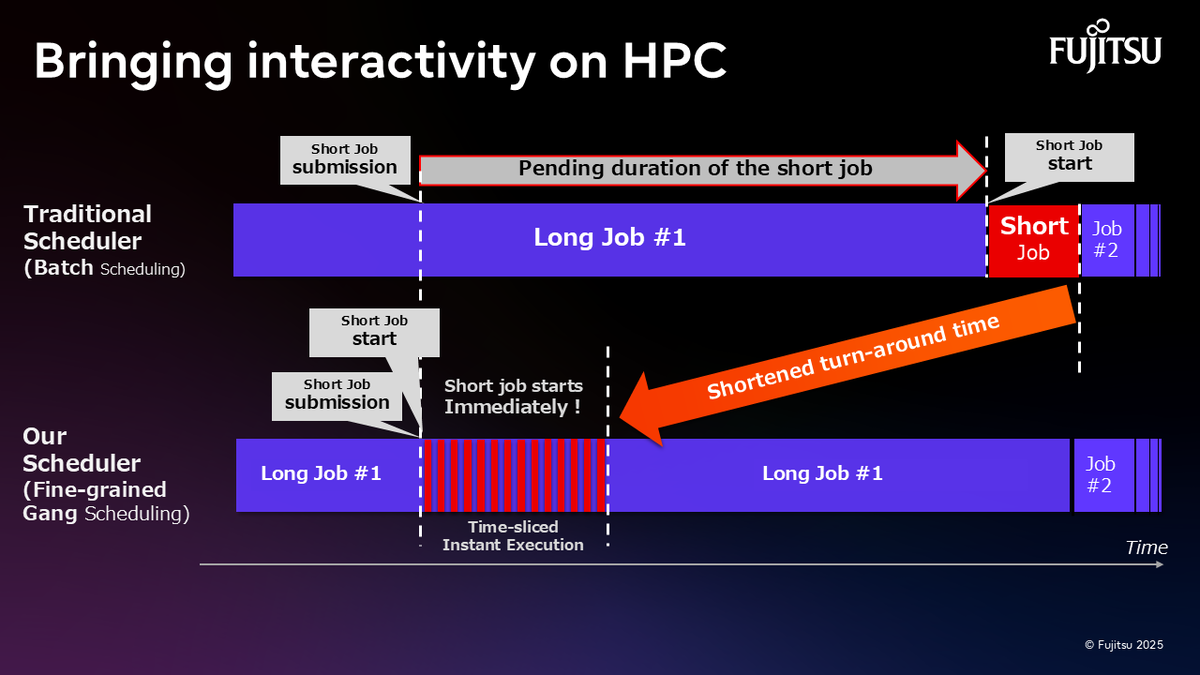
In fields such as generative AI and real-time analytics, there is growing demand for interactive computing, including iterative development and interactive analysis. However, traditional HPC environments rely on batch queuing systems for job execution, where computing resources are reserved and processed sequentially, meaning even short tasks must wait for long-running jobs to complete. The mismatch between interactive AI workloads and traditional HPC system characteristics is one of the challenges in AI-era computing.
The "Interactive HPC" technology developed by the Computing Laboratory addresses this challenge. This technology significantly reduces wait times by allowing short-duration jobs to preempt long-running jobs. Such approaches were traditionally considered difficult to apply to parallel applications, but by introducing high-precision inter-node synchronization technology, job states across all nodes are synchronized, supporting large-scale MPI applications.
Additionally, we presented new GPU transparent preemption functionality at this exhibition. This feature integrates GPU memory save/restore capabilities into the Slurm scheduler, temporarily evacuating running GPU job memory to host memory and enabling job switching without stopping applications. This allows short jobs to execute immediately without interrupting long-running jobs—not only for CPU jobs but also for GPU jobs including AI applications.
This technology is already in production use on a 1,056-node ARM cluster and the TSUBAME supercomputer at Institute of Science Tokyo. For details on the three technologies introduced at the exhibition, please refer to the following materials.
Reference Materials: SC25 Exhibition Materials (PDF)
Latest Trends in Supercomputer Rankings
Supercomputers are evaluated based on various metrics. Here we introduce trends from the TOP500 (computational performance), Graph500 (graph processing performance), and IO500 (storage performance) rankings.
TOP500: Computational Performance Ranking

TOP500 is a ranking that competes on system computational performance using the HPL (High Performance Linpack) benchmark, announced twice yearly. This time, the top 10 systems remained unchanged from the previous ranking, with U.S. systems maintaining the top three positions: 1st El Capitan, 2nd Frontier, and 3rd Aurora. While JUPITER Booster (Germany) in 4th place maintained its ranking, it significantly improved performance from 793 PFlop/s to 1 EFlop/s, achieving Europe's first exascale performance.
In Japan, RIKEN's supercomputer "Fugaku" ranked 7th globally and 1st in Asia (for the 12th consecutive time), also achieving 2nd place in HPCG and Graph500, and 8th in HPL-MxP. AIST's ABCI 3.0 and ABCI-Q ranked 16th and 32nd respectively, while SoftBank's CHIE-4 ranked 17th and JCAHPC's (University of Tokyo / University of Tsukuba) Miyabi-G ranked 42nd.
Graph500: Graph Processing Performance Ranking
In the Graph500 BFS ranking, "Fugaku," which had maintained the top position for 11 consecutive terms, dropped to 2nd place for the first time. The new 1st place is "eos-dfw," operated by U.S. cloud provider CoreWeave at their Dallas, Texas data center. For this benchmark run, they used 8,192 NVIDIA H100 GPUs (1,024 nodes) and recorded 410,266 GTEPS.
GPU technology continues to evolve year by year. Graph processing involves many random memory accesses, and traditionally CPUs—with their superior communication control and dynamic load balancing capabilities in large-scale distributed systems—had the advantage. However, recent advances in hardware such as NVLink and InfiniBand, along with software stack improvements including NVSHMEM (unified address space) and InfiniBand GPUDirect Async (communication bypassing CPU), have made efficient large-scale graph processing on GPUs possible.
Meanwhile, "Fugaku" tackled Scale 43 problems (8.8 trillion vertices, 141 trillion edges), which is 4 times larger than eos-dfw's Scale 41 (2.2 trillion vertices, 35 trillion edges). By continuing to tackle more challenging large-scale problems, it demonstrates its capability to handle complex real-world scientific computing applications. Additionally, in the HPCG benchmark measuring real application performance, Fugaku recorded 16.0 PFlop/s, maintaining 2nd place (1st is El Capitan at 17.41 PFlop/s). With its highly versatile CPU architecture, it continues to deliver reliable performance across a wide range of scientific computing applications, from weather forecasting to drug discovery.
What is particularly noteworthy is that while almost all current top-tier supercomputers are equipped with GPU accelerators, "Fugaku" maintains these high rankings with a CPU-only configuration. This is internationally recognized as demonstrating excellent architectural design and advanced optimization techniques. While GPU evolution is remarkable, the ability to design and develop high-performance CPUs in-house remains important for stability in large-scale distributed environments and adaptability to diverse applications and workloads. The optimization techniques for large-scale distributed systems and expertise in general-purpose CPU architecture are expected to be applied to next-generation system development.
IO500: Storage Performance Ranking
IO500 is a ranking that competes on storage system performance in the HPC field. This ranking includes categories for both Production and Research, with competitions for overall system performance as well as performance limited to 10 client nodes.
In the Production overall performance ranking, updates occurred at 2nd, 6th, and 9th places, with fewer systems adopting Lustre and more adopting DAOS as their file system. Nevertheless, Lustre is still used in two-thirds of the TOP100 systems, maintaining its position as the mainstream choice. From Japan, SoftBank's CHIE-4 and CHIE-3 ranked 9th and 10th respectively.
Exhibition Floor Highlights
At SC25, over 500 companies exhibited, filling the main venue to capacity and even using the adjacent stadium as additional exhibition space.
Growing Presence of Infrastructure Companies
Particularly striking was the new participation of major infrastructure companies specializing in cooling equipment and large-scale power supply. Several companies occupied some of the largest exhibition spaces, making them highly visible. As HPC and AI demand expands, liquid cooling and large-scale power supply have become essential infrastructure, and this scene symbolized the growing importance and expanding business opportunities in HPC.
AI Technology Becoming Concrete and Practical
"AI" was prominently featured as a keyword in many exhibits. Given limited time, I focused on memory and storage-related exhibits. Attention was drawn to AI storage systems supporting diverse interfaces, technologies extending GPU memory to petabyte-scale flash storage and distributed storage, and AI-oriented GPU memory expansion systems utilizing CXL (Compute Express Link) interconnect. These technologies have become more concrete than last year, increasingly discussed in the context of use cases such as LLM inference acceleration, and have gained significant presence.
The Changing Relationship Between AI and HPC
I felt that AI is no longer just one application area of HPC, but is now positioned as a core research topic in HPC. This being the third SC since entering the generative AI era, discussions have moved beyond basic topics like hallucination countermeasures and AI accuracy, now focusing specifically on "how to leverage AI for research," with implementation methods and utilization approaches becoming mainstream. As both researchers and companies recognize that AI adoption is essential for maintaining competitiveness, many exhibits reflected strong demand for infrastructure and middleware technologies to support this.
AI's Position in Scientific Research
A common message emerging from many presentations and discussions was that "AI is a collaborator for scientific researchers, a tool that extends human capabilities." Rather than aiming for complete autonomy, AI is positioned as a tool to accelerate and streamline scientists' work.
This year saw rapid development of AI agents. The keynote "Gigatrends: The Exponential Forces Shaping Our Digital Future" (by Thomas Koulopoulos) emphasized that we are in an unstable and uncertain era, where the time interval between opportunities or threats emerging and disappearing is shrinking. In this rapidly changing environment, reliable execution platforms that can operate autonomously and efficiently are essential for AI agents to quickly seize opportunities and respond immediately to threats. I strongly felt that building advanced technical foundations that enable effective human-AI collaboration is our mission as professionals in the HPC and AI fields.
Industry-Academia Collaboration Initiatives

As part of its industry-academia collaboration efforts, Fujitsu has established Small Research Labs jointly with domestic and international research institutions. At this event, we gave a presentation on Interactive HPC technology applications at the Institute of Science Tokyo booth, and conducted a joint exhibition on data store technology applications in the AI domain at the University of Tsukuba booth. Both introduced cases where developed middleware technologies were applied to actual computing platforms, demonstrating concrete examples of value delivered to real applications.
Summary
 This article introduced the exhibition technologies from Fujitsu Research's Computing Laboratory at SC25 and the latest trends in the HPC industry.
This article introduced the exhibition technologies from Fujitsu Research's Computing Laboratory at SC25 and the latest trends in the HPC industry.
The three GPU efficiency technologies introduced—ACB, LLM inference acceleration, and Interactive HPC—share a common goal of maximizing the utilization of expensive GPU resources. These middleware technologies make it possible to maximize the return on GPU investment and generate greater business value from the same hardware.
From the supercomputer rankings, we observed trends including the full-scale adoption of exascale systems, GPU evolution, and the development of AI-oriented data store technologies. In Graph500 specifically, while graph processing performance has dramatically improved through the latest GPU hardware and software optimization, we reconfirmed that "Fugaku" continues to play an important role with its versatility and stability.
Just three years after the full-scale adoption of generative AI began, it was impressive to see "AI" as a keyword scattered throughout the venue, with notable participation from physical infrastructure companies providing cooling equipment and power supply for AI's scale expansion. It was even said that "there are now more pump exhibits than processor exhibits," highlighting the growing importance of AI infrastructure. The focus of discussions has completely shifted from "Can AI be useful?" to the practical stage of "How do we implement and utilize it?"
In this rapidly evolving AI agent era, building advanced technical foundations that enable effective human-AI collaboration is our mission as professionals in the HPC and AI fields. Fujitsu Research's Computing Laboratory will continue to contribute to the development of computing infrastructure for the AI era that combines reliability and efficiency.
Start your ACB free trial here !
https://en-documents.research.global.fujitsu.com/ai-computing-broker/